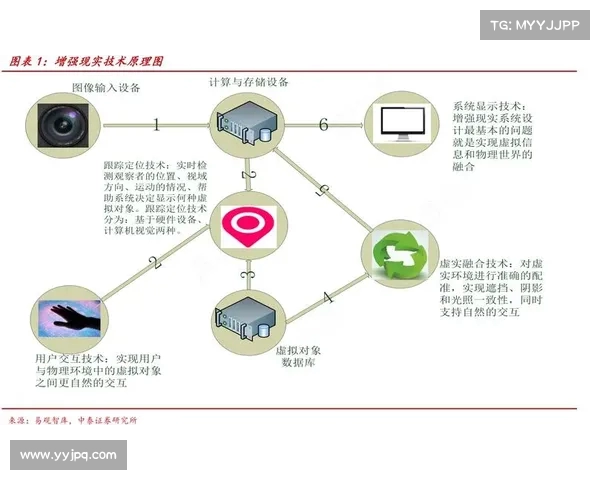
随着人工智能技术的快速发展,模拟人类真实声音并进行个性化调整已经成为了科技领域的一个重要应用方向。尤其是在语音合成、虚拟助手、娱乐等领域,AI模拟人声的技术正在不断突破和创新。通过深度学习算法、神经网络模型以及大量的数据训练,人工智能可以精准地模仿特定人的声音,并根据个性化需求进行细致的调整。这不仅提高了人机交互的自然度,还能为影视、广播、广告等多个行业提供定制化的声音服务。本文将从四个方面详细阐述如何利用人工智能技术模拟出一个人的真实声音并进行个性化调整,包括声音模拟的技术基础、数据采集与处理、个性化调整的方法以及应用场景分析。通过这些方面的深入探讨,我们可以全面理解这一前沿技术的实现过程及其未来发展前景。
1、声音模拟的技术基础
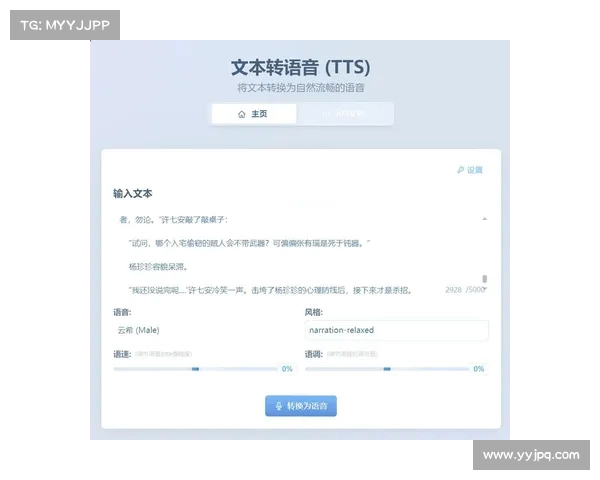
人工智能声音模拟的核心技术之一是语音合成(TTS, Text-to-Speech)技术。传统的语音合成方法大多依赖于预录音频库的拼接,通过拼接不同的音节、词语来产生语音。这种方法的局限性较大,声音的自然度和流畅度不高。随着深度学习技术的发展,基于神经网络的声学模型逐渐成为主流,这些模型能够学习到更为复杂和细腻的声音特征,使得合成的语音更具自然感和真实感。
目前,最常用的语音合成技术是WaveNet和Tacotron,它们通过深度卷积神经网络和循环神经网络对语音信号进行建模,从而能够生成更加流畅和真实的语音效果。WaveNet是一种基于时域建模的生成式神经网络,它能模拟音频波形的细节,从而生成具有高保真度的音频。而Tacotron则通过编码-解码结构将文本转化为音频谱图,再通过后续的声码器(如WaveGlow或HiFi-GAN)将其转化为语音。

这类技术的优势在于,它们不仅能模拟单一人的声音,还能够在多种场景下进行声音的风格化调节。例如,可以通过控制音高、语速、语气等参数,轻松生成符合需求的个性化声音。这种技术的突破使得AI模拟人声变得更加灵活与高效,广泛应用于虚拟助手、语音导航、语音翻译等领域。
2、数据采集与处理
在模拟真实声音的过程中,数据采集与处理是至关重要的一环。为了让人工智能更好地模仿特定人的声音,首先需要大量的语音数据。这些数据通常包括一个人说话时的音频文件,内容涵盖不同情感、语气、语速等多样化的语句。理想的语音数据集不仅要包含丰富的语音内容,还需要涵盖不同情境下的语音表达,以便AI能精确地模拟和重现该人的声音特征。
数据采集的方式一般包括专业录音设备的使用,以及语音采集系统的设计。为了提高数据的多样性,往往会让受试者进行不同情境下的发声,如情感激昂时、平静时、疑问时等。通过这些多角度的数据收集,人工智能可以在训练时学习到更丰富的声音特征,并且能够在不同情境下自如地调整语音输出。
此外,数据处理同样至关重要。在获得原始语音数据后,需要通过声音分析算法对数据进行预处理,包括去噪、分帧、特征提取等。这些步骤可以帮助AI更好地理解每个音素、音节以及语调的结构,从而在合成时实现更高的精度。通过这种精细化的数据处理,AI能够将人类的发音特征和情感表达更加准确地反映出来。
3、个性化调整的方法
声音的个性化调整是人工智能模拟人声的一大优势。通过对声音的多维度调节,AI可以生成满足不同需求的语音输出。这些调整通常包括音高、语速、语气、音色等多个方面。
音高的调整能够改变声音的“高低”感,适用于模拟不同性别或年龄段的声音。例如,较高的音高可以模拟儿童或女性的声音,而较低的音高则更符合男性或老年人的声音特点。语速的调整则控制着声音的快慢,能够根据不同场景和需求灵活调节。在快速对话或紧急场合中,语速加快可以提高信息传递的效率,而在讲解或叙述时,语速的放慢则能提升听众的理解力。
除了音高和语速,语气的调整也是个性化调整中非常关键的因素。通过模拟不同的情感和语气变化,AI可以让声音听起来更加生动和真实。例如,通过调节语气的起伏,可以模拟不同的情绪状态,如愉悦、愤怒、惊讶等。而音色的变化则能够对声音的质感进行精细的调整,使得合成的语音更加贴近特定人物的声音特征。
4、应用场景与挑战
人工智能模拟人声并进行个性化调整的技术已经在多个行业得到了广泛应用,尤其是在语音助手、智能客服、教育、娱乐和媒体等领域。例如,许多虚拟助手,如Siri、Alexa和Google Assistant,已经开始通过AI技术模拟人类声音,并根据用户需求进行调整,提供个性化的语音交互体验。
在娱乐行业,AI模拟人声的技术被广泛应用于电影配音、动画制作以及语音合成音乐等方面。例如,一些配音演员的声音可以通过AI技术生成,从而为动画角色或虚拟人物提供声音支持。而在智能客服和在线教育领域,AI语音助手能够根据用户的语调和语速偏好,自动调整语音输出,从而提高用户的体验。
然而,尽管技术已经取得了显著进展,AI模拟人声仍然面临一些挑战。最显著的挑战之一是如何更好地模拟声音中的细微情感变化,例如,如何让AI声音在悲伤、愉悦、愤怒等情绪下具有足够的表现力和真实性。此外,数据隐私和版权问题也是AI语音模拟应用中需要解决的重要问题。为了避免滥用和误用,未来的技术发展需要在保障隐私和合规性的前提下进行。
总结:
开云网站综上所述,人工智能模拟人声并进行个性化调整已经成为当前科技发展的前沿方向。通过语音合成技术、丰富的数据采集与处理、多维度的个性化调整,以及广泛的应用场景,AI在模拟人类声音方面取得了显著的成就。这项技术不仅极大地提高了人机交互的自然性,还在多个行业中提供了定制化、个性化的解决方案。
然而,AI模拟声音的技术仍然面临一些挑战,包括情感表达的精准度、数据隐私保护等问题。未来,随着技术的不断进步和完善,AI模拟声音的能力将更加成熟,能够在更广泛的应用场景中提供更加真实和个性化的声音体验。人工智能在模拟人声和个性化调整方面的潜力,必将在未来的生活和工作中发挥越来越重要的作用。